通过本教程,您可以了解如何使用DataWorks和MaxCompute产品组合进行数仓开发与分析,并通过案例体验DataWorks数据集成、数据开发和运维中心模块的相关能力。
注意事项
请确保操作账号拥有开通购买权限。阿里云主账号默认拥有该权限,若使用RAM子账号操作,请联系阿里云主账号前往RAM控制台,为RAM用户授权AliyunDataWorksFullAccess和AliyunBSSOrderAccess权限。具体操作,请参见为RAM用户授权。
环境准备
本教程以标准模式工作空间(开发、生产环境隔离)进行演示,请参考以下步骤准备一个DataWorks标准模式工作空间、一个具有公网能力的DataWorks资源组以及创建需要分别绑定为开发和生产环境计算资源的两个MaxCompute项目。
步骤一:服务开通
本教程以华东2(上海)地域为例进行演示,请根据您华东2(上海)地域的服务开通情况,进行环境准备操作。
未开通DataWorks服务
请参考以下操作在华东2(上海)地域开通DataWorks版本服务、开通MaxCompute产品服务,并准备DataWorks任务调度和服务运行所需的Serverless资源组。
进入服务开通页。
进入阿里云DataWorks官网,单击立即开通,即可进入DataWorks服务开通页。
开通服务。
请根据界面提示配置相关参数后,点击确认订单并支付,完成服务开通。
本案例选择开通(0元/月)DataWorks基础版服务,涵盖基本的数据集成、数据开发、调度能力,您也可根据业务实际需要的产品能力自行选择。
在选择DataWorks资源组时,您需要为资源组绑定可连通的专有网络,绑定后,DataWorks资源组默认可访问您指定专有网络下的云服务。您可自定义该资源组名称。
确认资源。
说明首次开通DataWorks服务,系统将会自动创建资源组,您需要确认资源组是否创建成功。
进入DataWorks资源组列表,在页面顶部切换地域为华东2(上海),确认已创建资源组。
已开通DataWorks服务
若您在华东2(上海)地域已开通过任意版本DataWorks服务,则需要手动创建资源组。
进入DataWorks资源组列表,在页面顶部切换地域为华东2(上海),单击新建资源组。
请根据界面提示配置相关参数后,单击立即购买,完成后续资源组购买。
说明资源组名称需要自定义,未配置时无法创建。
如果没有专有网络(VPC)和交换机(V-Switch),请根据页面提示前往专有网络VPC控制台创建。关于VPC和交换机的更多信息,请参见什么是专有网络。
首次购买资源组需要创建DataWorks服务关联角色。
确认资源。
进入DataWorks资源组列表,在页面顶部切换地域为华东2(上海),确认已创建资源组。
步骤二:为资源组开通公网
DataWorks已提供本案例涉及的原始数据供您体验,并提供其公网访问地址。若要在DataWorks访问该原始测试数据并确保本次实验可顺利开展,您需要确保您的DataWorks资源组已具备公网访问能力。
步骤一开通DataWorks服务时或手动创建的通用型Serverless资源组默认不具备公网访问能力,您需要通过公网NAT网关为资源组绑定的VPC添加EIP,使该资源组获得公网访问能力,具体操作参考下文。
登录专有网络-公网NAT网关控制台,在顶部菜单栏切换至华东2(上海)地域。
单击创建NAT网关,配置相关参数。
参数
取值
所属地域
华东2(上海)。
所属专有网络
选择资源组绑定的VPC和交换机。
您可以前往DataWorks资源组列表,切换地域后,找到步骤一已创建的资源组,然后单击操作列的网络设置,在数据调度 & 数据集成区域查看DataWorks资源组的绑定专有网络和交换机参数。VPC和交换机的更多信息,请参见什么是专有网络。
关联交换机
访问模式
VPC全通模式(SNAT)。
弹性公网IP
新购弹性公网IP。
关联角色创建
首次创建公网NAT网关时,需要创建服务关联角色,请单击创建关联角色。
说明上表中未说明的参数保持默认值即可。
单击立即购买,勾选服务协议后,单击确认订单,完成购买。
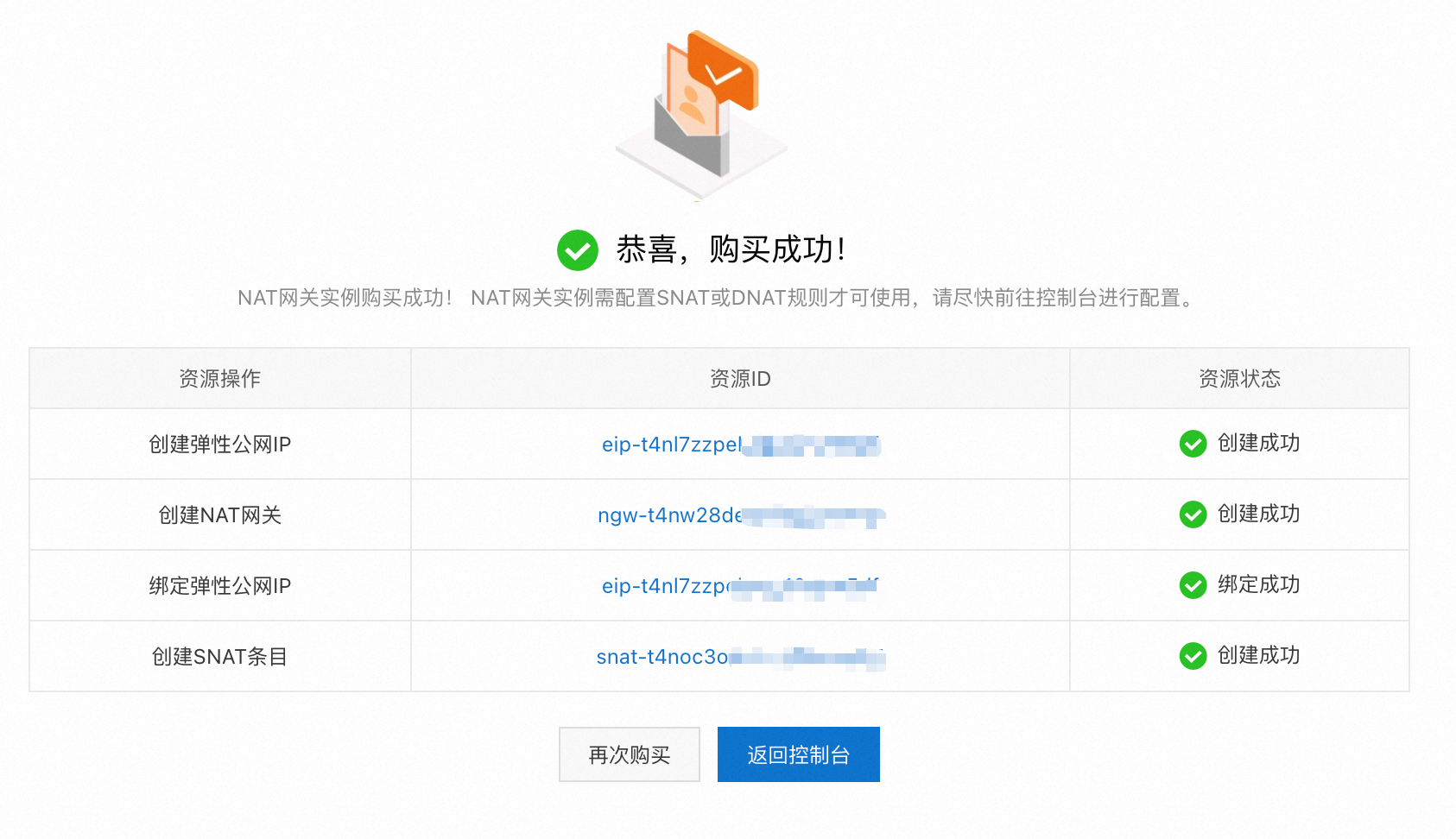
步骤三:创建工作空间
工作空间是DataWorks中进行任务开发、成员权限管理、协同开发的基本单元,DataWorks所有开发工作都将在工作空间内进行,您可参考以下内容准备为本案例创建DataWorks标准模式工作空间(开发、生产环境隔离)。
进入工作空间列表页。
进入工作空间列表,在页面顶部切换地域为华东2(上海),然后单击创建工作空间。
创建工作空间。以下为本教程所需配置的关键参数,未说明参数保持默认即可。
工作空间名称:自定义。
重要DataWorks工作空间名称全网唯一,您可以自定义工作空间名称或添加唯一标识作为后缀,避免因命名冲突而报错。
开发、生产环境隔离:开启此开关,指定空间模式为标准模式工作空间。
参加数据开发(Data Studio)公测:本教程是否开启均可进行,表示是否参加新版数据开发公测,推荐开启。
说明新版数据开发提供了实现面向多引擎协同的数据开发、可视化工作流编排和数据目录管理等能力,支持使用Notebook进行与AI联动的交互式数据探索与分析。关于新版数据开发的更多信息,请参见数据开发(Data Studio)(新版)。
2025年02月18日后,主账号在上海地域首次开通DataWorks并创建工作空间时,默认启用新版数据开发,无需配置此参数。
DataWorks工作空间默认资源组配置:设置为步骤一创建的资源组。
单击创建工作空间。
说明如果您在创建工作空间时选择了参加新版数据开发公测,则创建工作空间后会进入绑定计算资源引导页,此时暂不配置,单击完成或关闭即可。
步骤四:绑定MaxCompute为计算资源
MaxCompute侧:创建MaxCompute项目
本教程DataWorks使用标准模式工作空间(开发、生产环境隔离),需创建两个MaxCompute项目,作为开发环境和生产环境的计算和存储服务,请参考以下步骤完成这两个MaxCompute项目的创建。
MaxCompute项目名称全网唯一,不允许重名,您可以自定义项目名称或添加唯一标识作为后缀,避免因命名冲突而报错。
登录MaxCompute控制台,在左上角选择地域。
在左侧导航栏选择工作区 > 项目管理,并单击新建项目。
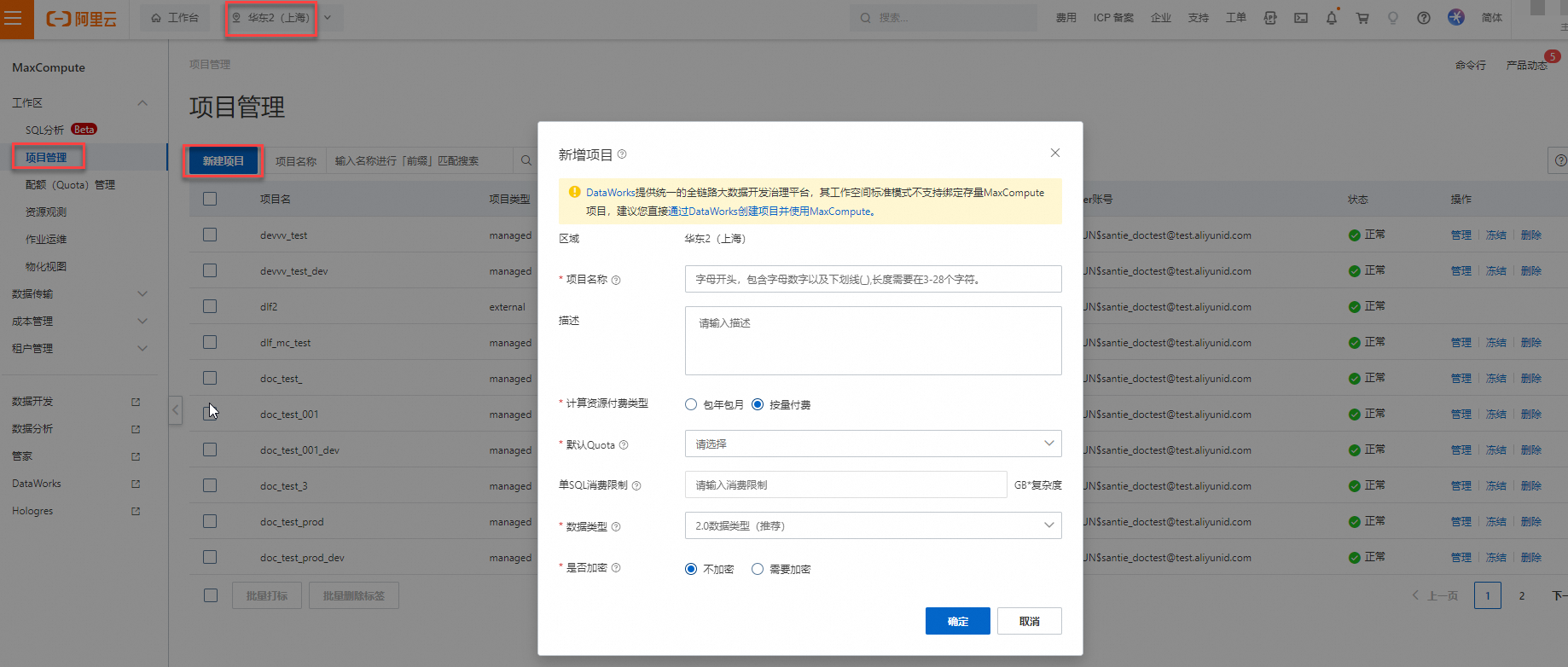
在新增项目对话框,根据界面提示文案配置项目信息后,单击确定。
其中需重点关注的配置参数如下,其他参数可参考界面提示文案进行配置。关于参数详情,您也可参见项目管理。
参数
描述
计算资源付费类型与默认Quota
您可根据已购买的MaxCompute的资源情况选择使用哪种。
包年包月
如果您已购买了包年包月的MaxCompute资源,您可将资源做好Quota规划,为本项目选择后续作业运行需要使用的包年包月资源Quota。Quota规划与管理请参见计算资源-Quota管理。
按量付费
MaxCompute开通时默认购买的为按量计费标准版的MaxCompute,如果您没有购买其他MaxCompute资源,可选择按量付费,并选择默认后付费Quota。
创建成功后,即可在左侧导航栏的工作区 > 项目管理中查看新创建的MaxCompute项目。
DataWorks侧:绑定MaxCompute为计算资源
在标准模式工作空间(开发、生产环境隔离)内,需绑定已创建两个MaxCompute项目,分别作为开发环境和生产环境的计算和存储服务,请参考以下步骤完成开发环境与生产环境的计算资源绑定。
进入DataWorks-工作空间列表页,找到已创建的工作空间,单击工作空间名称,进入空间详情页。
在左侧导航栏单击计算资源。
如果是新版数据开发,则单击绑定计算资源,选择MaxCompute类型。
如果是旧版数据开发,则页面会跳转至数据开发计算资源页面,单击新建计算资源,选择MaxCompute类型。
根据页面提示绑定MaxCompute计算资源。
关键参数说明:
计算资源名称:您可以自定义,用于表示此MaxCompute计算资源。
所属云账号:配置为当前阿里云主账号。
地域:选择与当前DataWorks空间一致的地域华东2(上海)地域。
MaxCompute项目名称:选择华东2(上海)地域下已创建的两个MaxCompute项目,分别作为生产环境和开发环境的MaxCompute项目。
重要生产环境与开发环境需绑定不同的MaxCompute项目,保证生产环境与开发环境之间的隔离。
默认访问身份:开发环境默认为执行者,生产环境本教程选择为阿里主账号。
说明如果您当前登录的是其他身份账号,具体配置请参见创建MaxCompute数据源。
单击确认(新版数据开发)或新建计算资源并绑定数据开发(旧版数据开发)。
任务开发
本教程以网站用户画像分析为例,为您介绍如何通过DataWorks和MaxCompute产品组合实现具体业务开发与周期调度。
步骤一:流程设计
网站用户行为分析案例通过DataWorks数据集成模块的离线同步能力,将业务数据同步至MaxCompute,然后通过DataWorks数据开发模块的MaxCompute SQL节点完成用户画像的数据加工,最终将加工结果写入ads_user_info_1d表。业务数据包括:
存储于MySQL中的用户基本信息(ods_user_info_d),平台默认提供,无需开通,将访问信息以添加数据源的方式配置到您的空间即可在您空间下访问这份数据。
存储于OSS中的网站访问日志数据(user_log.txt),平台默认提供,无需开通,将访问信息以添加数据源的方式配置到您的空间即可在您空间下访问这份数据。

步骤二:任务开发
基于步骤一:流程设计,在DataWorks完成工作流的任务开发。DataWorks已提供本教程的相关代码,您可参考以下操作通过一键导入快速体验该案例。后续您也可参考用户画像分析(MaxCompute版)逐步实操进行体验。
登录DataWorks控制台,单击左侧导航栏的,然后在类别中选择Workflow。单击网站用户画像分析卡片。
载入案例。
在案例详情页,单击载入。然后根据页面指引完成案例载入。
关键参数说明:
确认载入结果。
在载入案例页面,单击确认后将自动开始载入,您可以在页面弹窗中查看导入进度,所有内容导入完成后,您可以单击前往查看。
说明关闭导入进度窗口,不会影响模板的导入,您可以在工作空间详情页,单击左侧导航栏的或数据开发,前往数据开发模块查看导入的模板内容。
查看案例介绍。
新版数据开发:在左侧导航栏单击
 ,即可看到已导入的
,即可看到已导入的用户画像分析案例,单击打开工作流面板。您可以双击工作流的第一个节点(
 案例介绍_用户画像分析),查看该工作流的案例背景和各节点加工逻辑说明等。
案例介绍_用户画像分析),查看该工作流的案例背景和各节点加工逻辑说明等。旧版数据开发:在数据开发的业务流程下,双击
体验案例1_用户行为分析,打开业务流程画布。您可以双击画布中业务流程的第一个节点(
 用户行为分析案例说明),查看该业务流程的案例背景和各节点加工逻辑说明等。
用户行为分析案例说明),查看该业务流程的案例背景和各节点加工逻辑说明等。
说明在首次业务流程执行成功前,打开离线同步任务节点(
 )会因同步目标MaxCompute表不存在而报错,您可以先手动运行上游节点(
)会因同步目标MaxCompute表不存在而报错,您可以先手动运行上游节点(table_ddl_ods_raw_log_d和table_ddl_ods_user_info_d),创建目标表后,再查看离线同步详情。
步骤三:任务运行
任务开发完成后,可通过以下方式确认代码及流程是否符合预期。
运行用户画像分析流程。
导入的案例为完整案例,您可以在工作流或业务流程页面顶部,单击运行按钮运行整个流程。
说明如果是新版数据开发,单击运行后,需要您在填写运行参数页面配置本次运行值,格式为
yyyymmdd,表示业务日期,一般配置为当前日期的前一天,例如配置为20250302。查看业务流程运行过程。
请耐心等待,确保所有任务节点均运行成功后(状态均为
 ),再进行后续步骤。说明
),再进行后续步骤。说明如果是新版数据开发,需在页面顶部单击返回,回到工作流面板后,再进行后续步骤。
确认用户画像数据。
单独运行最后一个任务节点,即可查看最终产出的用户画像数据。
在工作流或业务流程页面,双击流程中最后一个节点,进入节点详情页面,选中如下SQL语句,在页面顶部单击运行,查询
ads_user_info_1d表,获取最终的用户画像数据。SELECT * FROM ads_user_info_1d where dt = '${bizdate}' LIMIT 10;如果是新版数据开发,运行工作流时已配置本次运行值,此处查询时
bizdate指定的分区日期请与运行工作流时配置的运行值一致。如果是旧版数据开发,运行业务流程时无需配置业务日期,默认为当前日期的前一天,则此处查询中,
bizdate指定的分区日期请配置为当前日期的前一天。
说明DataWorks提供调度参数,可实现代码动态入参,您可在SQL代码中通过
${变量名}的方式定义代码中的变量,并在调度配置>调度参数处,为该变量赋值。调度参数支持的格式,详情请参见调度参数支持的格式。本案例的SQL中使用了调度参数${bizdate},表示业务日期为前一天。若查询的分区没有数据或报错分区不存在,请通过日志查看代码中的
${bizdate}替换情况,明确数据最终写入的分区。
任务运维
步骤一:任务发布至生产环境
待数据开发中用户画像分析流程运行无误后,您可以将整个流程发布至生产调度系统进行周期性自动调度运行。
如果您在导入案例时选中了自动发布选项,则无需手动配置。
如果您在导入案例时未选中自动发布,请手动将任务发布至生产环境。
新版数据开发:在工作流页面顶部,单击发布,打开发布面板。单击开始发布生产,根据发布流程引导,单击确认发布到生产环境,完成发布。
旧版数据开发:在业务流程页面顶部,单击提交,然后单击发布,根据页面提示,完成发布。
步骤二:查看生产调度任务
任务发布后,您可在页面查看空间下所有周期性调度的任务,并在此对周期任务执行相关运维操作。
在左上角单击
 > 全部产品 > 数据开发与运维 > 运维中心(工作流)。
> 全部产品 > 数据开发与运维 > 运维中心(工作流)。在左侧导航栏单击,您可以查看空间下所有处于调度系统中的任务,通常,这些任务都将按照调度配置情况自动调度。您可以周期任务中确认生产环境的任务状态,包括但不限于:
生产任务依赖关系:单击案例介绍_用户画像分析(新版数据开发)或用户行为分析案例说明(旧版数据开发)任务名称,进入DAG面板,在第一个节点上右键,选择,快速查看任务的上下游依赖关系。
生产任务详情:双击DAG图任意节点可快速展开节点属性面板,您可以在此查看节点的基本信息、节点责任人、执行时间、操作日志以及调度运行的代码等。
如果该界面未找到任务,请参考步骤一:任务发布至生产环境手动执行任务发布操作。
步骤三:补数据回刷去年同期数据
补数据可通过补充历史或未来一段时间的数据,将写入数据至对应时间分区,可实现指定业务日期的数据处理,主要用于历史数据回刷。
本教程通过补数据功能将业务库去年同期的数据回刷至MaxCompute,并在MaxCompute完成历史同期的用户画像数据加工。
在周期任务列表找到案例介绍_用户画像分析(新版数据开发)或用户行为分析案例说明(旧版数据开发)节点,右键选择。
在补数据页面配置相关参数。
关键参数说明:
补数据包含当前任务:配置为是。
选择下游节点:全选下游节点。
业务日期:配置为去年的同期业务日期。
单击提交并跳转,查看补数据任务是否成功。
DataWorks通过实例的方式运行离线调度任务,对任务执行补数据操作后,您可查看实例详情确认补数据任务执行情况。
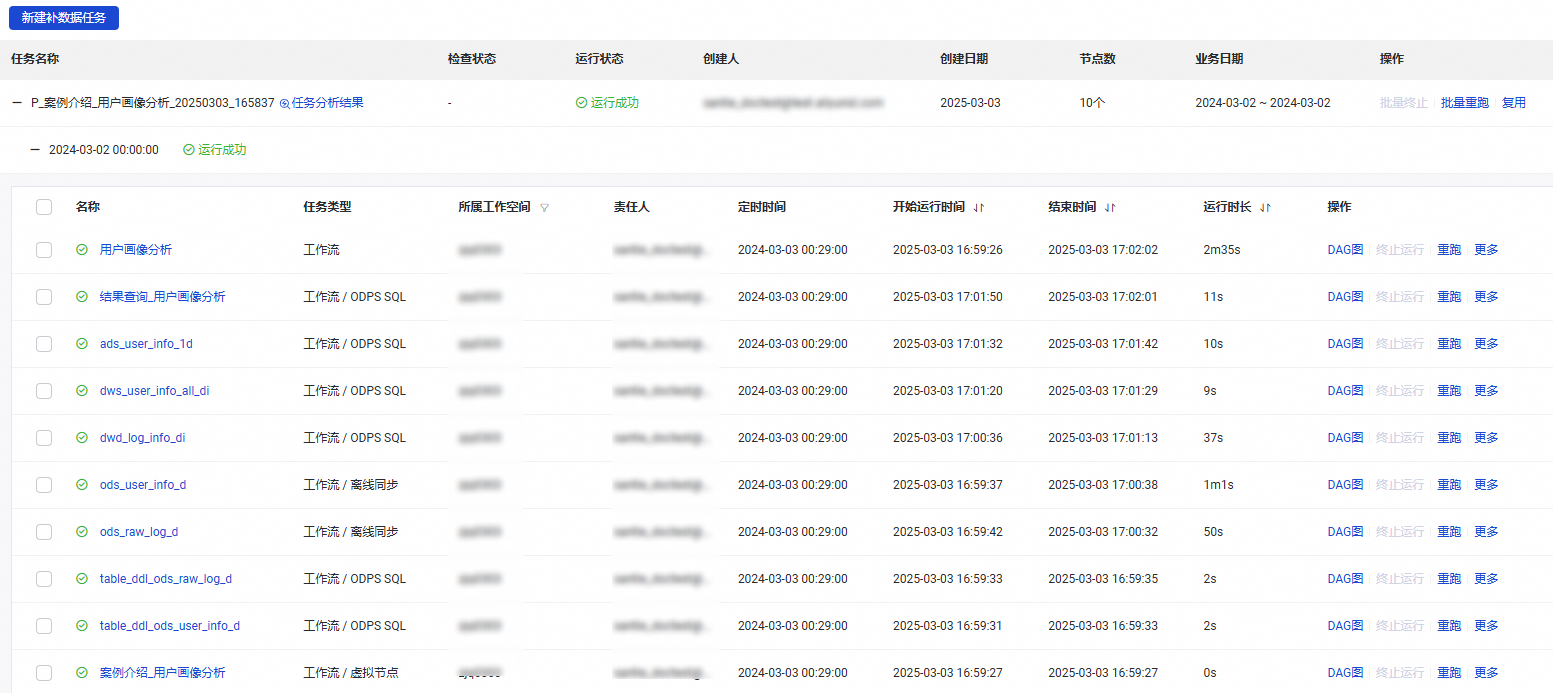
您可以单击某个任务,然后单击查看日志。
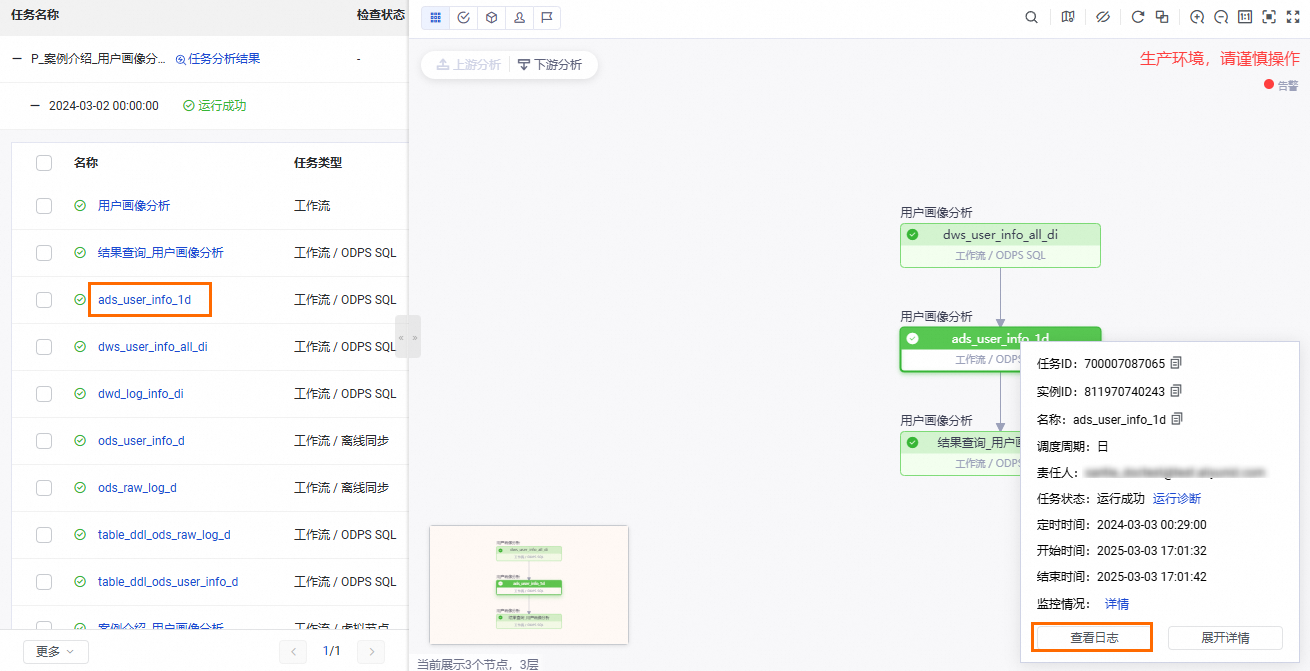
确认数据写入的MaxCompute表及分区。
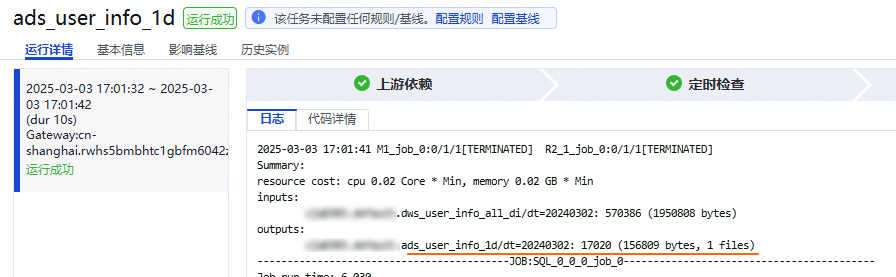
后续:查看任务周期调度情况
周期任务列表中的任务将通过实例的方式运行,周期任务自动调度将生成周期实例,调度周期不同,每日生成的实例个数不同。后续任务正常调度后,您可以在左侧导航栏单击,查看单个实例的运行情况。
小时任务定义
00:00~23:59之间,每小时调度一次,那么在周期实例界面每天将生成24个小时实例,每个实例有自己的实例ID作为唯一标识,同一个任务产生的所有实例的任务ID(节点ID)相同。若周期调度任务运行异常,可查看实例日志快速定位异常原因。
任务查询
待补数据实例运行完成后,请前往SQL查询,通过查询SQL,获取用户画像分析业务流程通过补数据产出的去年同期的分区数据。
在左上角单击
> 全部产品 > 数据分析 > SQL查询。在我的文件下创建查询文件。
使用如下SQL,查询生产表
ads_user_info_1d去年同期的数据。SELECT * FROM <生产项目名称>.ads_user_info_1d where dt = '<生产表实际被写入的分区>';运行前,需在窗口右上角选择计算资源。
说明如何查看DataWorks空间生产环境绑定的MaxCompute项目,请参见步骤四:绑定MaxCompute为计算资源。
DataWorks默认RAM用户无权限访问生产项目下的表数据,若您查询生产表数据报错无权限,需要前往安全中心申请,详情请参见:MaxCompute数据访问权限控制。
资源释放
为避免后续产生费用,您可参考本节将本教程创建的资源释放。
停止周期任务自动调度。
进入运维中心页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入运维中心。
在中,勾选所有之前创建的周期任务,然后在底部单击暂停(冻结)。
(可选)如果您不再需要本教程的调度任务,可以单击。
删除公网NAT网关并释放弹性公网IP。
说明公网NAT网关和弹性公网IP不使用也会收取配置费用(计费详情请参见公网NAT网关计费、弹性公网IP计费),建议不再使用时及时删除,如后续还需运行本教程的业务流程或执行调度,可再次为资源组绑定的VPC配置NAT网关和弹性公网IP,具体操作请参见步骤二:为资源组开通公网。
登录专有网络-公网NAT网关控制台,在顶部菜单栏切换至华东2(上海)地域。
找到已创建的公网NAT网关,单击操作列的
 > 删除,在确认窗口中,选中强制删除,然后单击确定。
> 删除,在确认窗口中,选中强制删除,然后单击确定。在左侧导航栏单击,找到已创建的弹性公网IP,单击操作列的
> 释放,在确认窗口中,单击确定。